Automatic Cluster Performance Shifts Detection Toolkit
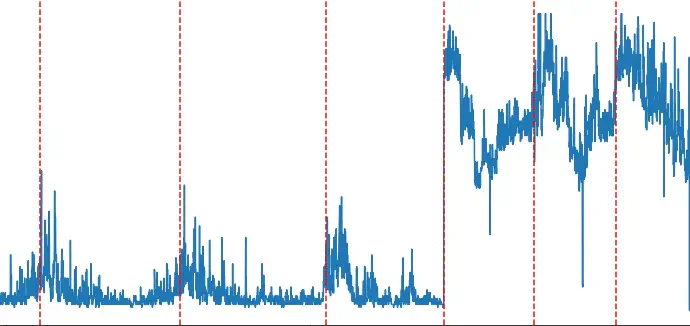
High-performance computing (HPC) clusters typically suffer from performance degradation over time. The heterogeneous nature of clusters and the inevitable defects in various infrastructure layers will result in a harder performance prediction inside. On the other hand, when software upgrades or any such events happen, we might also observe performance improvement or degradation even though nothing changes in the hardware. Due to these uncertainties, it is necessary to send early notification to administrators of changes in cluster performance in a specific time window to inform scheduling decisions and increase cluster utilization.
We are targeting HPC clusters that cater to heterogeneous, compute, and I/O intensive workloads that range from scientific simulation to AI model training that have high degree of parallelization in their workloads. In this scenario, we plan to use the Darshan open-source toolkit (https://github.com/darshan-hpc/darshan) as data collection or profiling tools to design our performance drift algorithms. Furthermore, we will possibly incorporate the distribution shift detection into Darshan, making it viable as a notification to the HPC system administrators.
Our goal is to show the efficacy of our algorithm by plotting the profiling data that display specific time windows where the performance shifts happened after being processed by our algorithm. Finally, we will package all our profiling data and experiment scripts inside Jupyter notebook, especially Chameleon Trovi, to help others reproduce our experiments.
Through this research, we seek to contribute the following:
- Designing an algorithm to detect performance shifts in HPC clusters that can be adapted for heterogeneous workloads
- Real-time detection of the performance shifts without introducing great overheads into the system
- Contribute to Darshan to be able to automatically detect performance changes while profiling the clusters.
Automatic and Adaptive Performance Shifts Detection
- Topics: Statistical Machine Learning, Deep Learning, and High-Performance Computing (HPC)
- Skills: C++, Python, Statistics, good to have: Machine Learning, Deep learning
- Difficulty: Moderate
- Size: Large (350 hours)
- Mentors: Sandeep Madireddy (https://www.anl.gov/profile/sandeep-r-madireddy, http://www.mcs.anl.gov/~smadireddy/ ), Ray Andrew Sinurat (https://rayandrew.me)
- Contributor(s): Kangrui Wang
All in all, these are the specific tasks that the student should do:
- Collaborate and work with mentors to understand the goal of this project.
- Implement distribution shift detection in pure statistical or machine/deep learning
- Deploy the algorithm and try to see its efficacy in the clusters.
- Package this experiment to make it easier for others to reproduce
Sandeep Madireddy
Computer Scientist at Argonne National Laboratory
Sandeep Madireddy is a Computer Scientist in the Mathematics and Computer Science Division at Argonne National Laboratory
Ray Andrew Sinurat
PhD Student, University of Chicago
Ray Andrew Sinurat is a PhD student at the Department of Computer Science at the University of Chicago