Learning Machine Learning by Reproducing Vision Transformers
Using Reproducibility in Machine Learning Education

Hello again!
In this blog post, I will be discussing the second material I created for the 2023 Summer of Reproducibility Fellowship. As you may recall from my first post, I am working on the Using Reproducibility in Machine Learning Education project with Fraida Fund as my mentor. My goal is to create interactive open-source educational resources that teach reproducibility and reproducible research in machine learning (ML), as outlined in my proposal.
In this post, I will share with you my second material, and how it can be helpful in machine learning class to teach students about vision transformers and reproducibility at the same time. If you haven’t seen my first work, be sure to check out my previous blog post. Without further ado, let’s dive in!
Reproducing “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”
This material is a reproduction of Dosovitskiy et al.‘s 2020 paper, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale”. This paper introduces the Vision Transformer (ViT), a novel architecture that applies the transformer model, originally designed for natural language processing tasks, to image recognition. The ViT model achieves state-of-the-art performance on several image classification benchmarks, demonstrating the potential of transformers for computer vision tasks.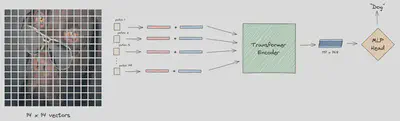
To reproduce this paper, I followed a systematic approach to ensure reliable results:
- Critically analyze the paper’s qualitative and quantitative claims.
- Identify the necessary experiments to verify each claim.
- Determine the required data, code, and hyperparameters for each experiment.
- Utilize pre-trained models for validating claims that require high computational resources.
- Investigate resources shared by the authors, such as code, data, and models.
- Assess the feasibility of verifying different types of claims.
- Design new experiments for validating qualitative claims when certain models or datasets are unavailable.
I utilized Chameleon as my platform for conducting and documenting my reproduction experiments. Chameleon is a large-scale, reconfigurable experimental environment that supports computer science systems research. It enables users to create and share Jupyter notebooks capable of running Python code on Chameleon’s cloud servers. For this work, a GPU with 24GB or more memory is required to run the notebooks on GPU, which Chameleon offers in its variety of GPUs.
I have set up a GitHub repository where you can access all of my reproduction work. The repository contains interactive Jupyter notebooks that will help you learn more about machine learning and the reproducibility of machine learning research. These notebooks provide a hands-on approach to understanding the concepts and techniques presented in my reproduction work.
Challenges
Reproducing a paper can be a challenging task, and I encountered several obstacles during the process, including:
- The unavailability of pretraining datasets and pretrained models
- Inexact or unspecified hyperparameters
- The need for expensive resources for some hyperparameters
- The use of different frameworks for baseline CNNs and Vision Transformers
These issues posed significant difficulties in replicating the following table, a key result from the Vision Transformer paper that demonstrates its superiority over prior state-of-the-art models.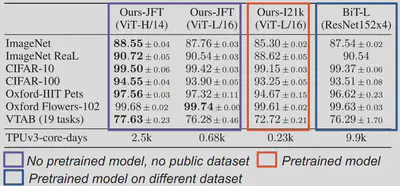
To overcome these challenges, I used the same models mentioned in the paper but pretrained on different datasets, experimented with various hyperparameter combinations to achieve the best results, and wrote my own code to ensure that both the baseline and Vision Transformer were fine-tuned using the same framework. I also faced other challenges, which I discussed in my notebooks along with the solutions I applied.
How to use this material?
This material consists of a series of notebooks that guide you through the paper, its claims, experiments, and results. You will learn how to analyze, interpret, and validate the authors’ claims. To get started, I recommend briefly skimming the original paper to gain an understanding of the main ideas and public information. This will help you see how the authors could have been more transparent and clear in certain sections. The notebooks provide clear instructions and explanations, as well as details on how I addressed any missing components.
Conclusion
In this blog post, I’ve walked you through the contents of this material and the insights users can gain from it. This material is particularly intriguing as it replicates a paper that has significantly influenced the field of computer vision. The interactive nature of the material makes it not only educational but also engaging and enjoyable. I believe users will find this resource both fun and beneficial.
I hope you found this post informative and interesting. If you have any questions or feedback, please feel free to contact me. Thank you for reading and stay tuned for more updates!
Mohamed Saeed
Computer and Communications Engineering student
Computer and Communication Engineering student interested in NLP and machine learning research