Kolmogorov-Arnold-based Transformer for LLMs
Implementation, Evaluation and Benchmarking
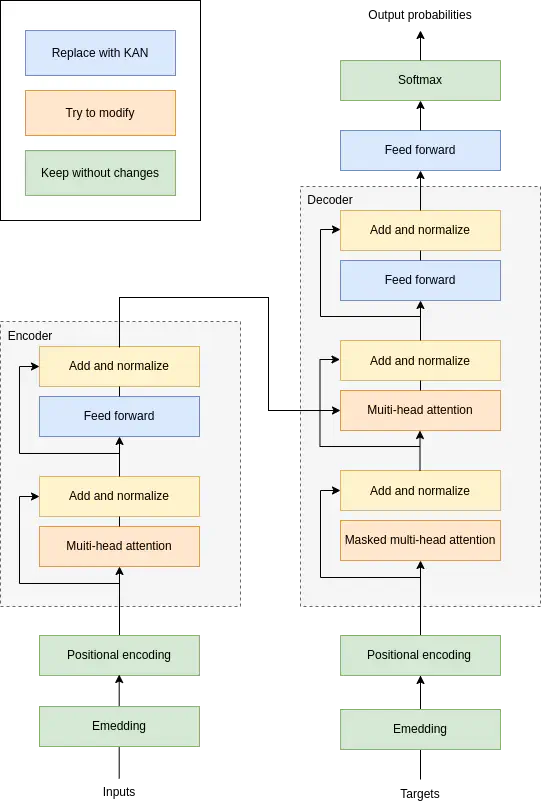 Architecture of the Transformer with suggested modifications.
Architecture of the Transformer with suggested modifications.Project: KALLM
Proposal: proposal
Mentors:
- Sai Suman Lamba Karanam
- Prof. Zahmeeth Sakkaff
I am modifying existing large language models to make them more efficient by replacing some of their layers with Kolmogorov-Arnold Network (KAN) modules. These KAN layers use compact univariate polynomial approximations, which can reduce parameter count and improve interpretability. The project explores how to integrate these layers into Transformers, and how far we can push this idea by combining or stacking KAN modules with different polynomial bases. The goal is to keep performance competitive while lowering computational costs.
Beyond just speeding up training, I am exploring several other promising directions. One is testing whether transfer learning remains effective when replacing the linear layers of a pretrained LLM with KAN modules, or when swapping between different KAN configurations. I am also considering curriculum learning strategies that gradually increase KAN complexity during training. I have studied all major KAN implementations and early experiments with a custom Transformer architecture show encouraging results. However, I have found that most LLMs rely on functional-style activation definitions in PyTorch, which makes it difficult to build a universal wrapper. Because of this, KAN-based models will likely need to be integrated manually on a case-by-case basis.